Kaggle Tweetコンペ振り返り - コンペ概要・BERTによるQ&Aアプローチについて
はじめに
本記事では2020年3月~6月にかけて開催され、約2200チームが参加したKaggleのコンペ Tweet Sentiment Extraction(通称Tweetコンペ)について、振り返りを兼ねてまとめたいと思います。

コンペ概要

まず初めに本コンペのポイントをいくつか挙げます
- Sentimentラベルの与えられたTweetから、そのSentimentに該当する箇所を抜き出す課題。
- アノテーションの問題で正解ラベルにノイズが多く含まれており、noisy labelへの対処もポイントとなった。
- BERTやRoBERTa等の言語モデルによるQuestion Answeringアプローチが解法として多く用いられた。
1点目の課題設定についてですが、各ツイートにはneutral, positive, negativeのどれかがSentimentラベルとして付与されていて、それに該当する部分を特定する問題となっています。
2点目について、アノテーターによって抜き出された正解ラベルにはいい加減なものも多く、例えば単語の途中で途切れていたり、似たような内容でも抜き出された箇所が違っていることがあります。Trainデータのうちおよそ10%にはそのようなnoisyな正解ラベルが含まれていました。
正解ラベル例:
Tweet: Happy Mothers Day to all the Mommys.
Answer: Happy Mothers Day to all the Mommys.Tweet: Happy Mothers Day! Same day, more chocolate
Answer: Happy Mo3点目について、BERTやRoBERTa等の言語モデルによって、SentimentをQuestionとして捉えてTweetから対応する箇所を答えるQuestion Answeringタスクとしてこの課題を解く取り組みがGMによるnotebookをはじめとして広く行われていました。
データ
データ数について
Trainには約27000ツイート、Public Testには約3000ツイートが含まれていて、Private TestはPublicの3倍程度のデータが含まれています。各ツイートにはsentimentラベルとselected_text(正解ラベル)が設定されています。
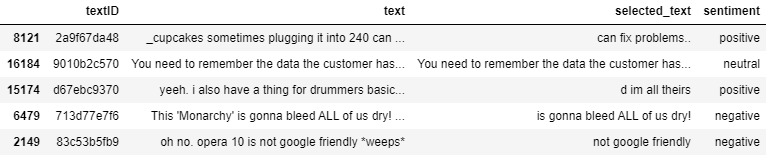
Sentimentについて
Sentimentラベルはneutral, positive, negativeの3種類からなります。内訳は以下のようになっていて、neutralが多く存在していることが分かります。

出典:https://www.kaggle.com/tanulsingh077/twitter-sentiment-extaction-analysis-eda-and-model
このneutralツイートですが、selected_textのほとんどが元のtweetそのままであることが多く、実は予測するのが非常に簡単です。実際、neutralの予測をtweetそのままにするだけでも(neutralに関しては)96.9%のスコアを出すことができます。したがってnegativeとpositiveをいかに上手く予測するかがポイントの一つになっていました。
元データについて
コンペの説明文に
In this competition we've extracted support phrases from Figure Eight's Data for Everyone platform. The dataset is titled Sentiment Analysis: Emotion in Text tweets with existing sentiment labels
とある通り、今回のデータはSentiment Analysis: Emotion in Text tweets with existing sentiment labelsという既存のデータセットを元に新規にラベル付けしたものです。
元のデータ数は40000件のツイートで、今回のコンペデータ数がtrainデータ27000+public testデータ3000+α(private)であることを考えるとそのほとんどがコンペデータとして使われていることが推測できます。したがってCode competitionでありながらPrivate dataの様子が多少分かるという状態になっています。
しかしながら、
- 正解ラベルのselected_textは新規にラベル付けされたもの
- コンペデータと元データではsentimentの付与のされ方が異なる
などの理由から完全なLeak状態にはなっておらず、Private dataにどのようなツイートが存在しているかなどの情報が分かる程度でした。
評価指標
評価指標はword-level Jaccard scoreで以下の式で表されます。
これは予測と正解の単語全体の中で共通の単語が占める割合を示しています。
具体的に考えてみます。
だとすると、
となるのでこの場合のJaccard scoreは2/4=0.5となります。
コードで表すと以下のようになります。
def jaccard(str1, str2):
a = set(str1.lower().split())
b = set(str2.lower().split())
c = a.intersection(b)
return float(len(c)) / (len(a) + len(b) - len(c))このJaccard scoreをツイートごとに計算し、平均をとったものが最終的なスコアとなります。
BERTによるQ&Aアプローチ
Question Answeringについて
今回のコンペではGMによるnotebookをはじめとして、BERTやRoBERTa等の言語モデルによるQuestion Answeringアプローチが数多く試みられていました。
Question Answeringタスクにおけるデータはテキストと質問文と正解の3つからなります。例えば有名なデータセットであるSQuADではWikipediaの記事から質問の答えとなる部分を正解として抜き出すことが目的となっています。
本コンペにおけるアプローチ
今回のコンペでは、元のツイートがテキスト、sentimentが質問文、selected_textが正解にそれぞれ該当します。BERTによるQAアプローチでは1文目を質問文(sentiment)、2文目をテキスト(ツイート)としてinputとします。BERTの出力側のhead部分では正解となる箇所のStart indexとEnd indexをそれぞれ確率で予測します。そして最も確率の高くなったStartとEnd部分を抜き出すことで最終的な予測結果となります。

BERTによるQAアプローチ
QAアプローチの課題
BERTによるQAアプローチではtokenizerで分割した単語をインプットとし、それに対してstartとendのindexを予測するため、予測する箇所によってはどうしてもselected_textと一致しなくなる場面が出てきます。
例えば、RoBERTaのtokenizerで"i'm so sad..."を分割すると"i/'m/so/sad/..."と分割されます。しかし、この場合selected_textが"sad."のようにsad+ピリオドが1つとなる時に上手く予測することができません。仮に"sad..."と予測できたとしてもピリオドの数が異なるためjaccard scoreは0となってしまうからです。

このような課題やnoisy labelへの対処法として有効なpost-processing(通称magic)を見つけようとする試みが、コンペ終盤には盛り上がっていました
最後に
本記事ではTweetコンペの振り返りということで、コンペの概要からBERTによるQ&Aアプローチまで簡単にまとめました。上位陣の解法を読む際などにお役立て頂ければと思います。
Kaggle 分子コンペ振り返り - コンペ概要・GCNの適用について
はじめに
本記事では2019年6月~8月にかけて開催され、約2800チームが参加したKaggleのコンペ Predicting Molecular Properties(通称分子コンペ)について、振り返りを兼ねてまとめたいと思います。
www.kaggle.com

コンペ概要
まず初めに本コンペのポイントをいくつか挙げます。
- 分子内の2つの原子間の磁気的相互作用(scalar coupling constant、以下sc)を予測する問題。
- trainとtestで共通して与えられたfeatureは分子の構造ファイル(xyzファイル)のみ。
- 原子と結合からなるグラフと見なせる分子データを扱うにあたりGraph Convolutional Networks(GCN)が活用された。
1点目の問題設定についてですが、磁気的相互作用scの予測となっています。scは量子化学計算によって3次元の分子構造から正確に求めることができますが、非常に計算コストが高い(1分子あたり1日〜1週間)ことが知られています。機械学習を用いてscを簡便に求める方法が見つかれば、医薬品化学分野などに役立てることができると考えられます。
2点目についてはtrainとtestで共通して与えられたfeatureは各原子の種類や位置情報を含んだxyzファイルのみで、特徴量の作成においては後述する外部ライブラリーの利用が必要となりました。
3点目についてですが、グラフ構造と見なせる分子データを扱うにあたって、近年注目を集めているGCNが活用され(GBTを上回る?)高い性能を示した興味深いコンペとなりました。
データ
データ数について
分子数は約13万個でtargetとなるscの値はtrain約460万、test約250万となっています。
xyzファイルについて
trainとtestに共通するfeatureとして原子数や分子名、分子内の原子の座標情報などを含んだxyzファイルが与えられています。これだけでも位置情報を元にした特徴量(例:2つの原子間距離)は比較的容易に作成できますが、RDKitやDScribeのような外部ライブラリを使用することで分子の特徴を化学構造に基づいて数値として表す記述子を更に作成することができます。
scalar couplingについて
targetとなるscは2つの原子間の磁気的相互作用ですが、2つの原子の組み合わせによって以下の8つのタイプに分けられています。
1JHC, 2JHC, 3JHC, 1JHN, 2JHN, 3JHN, 2JHH, 3JHH
例えば1JHCは隣あうHとC(例:H-C)、2JHNは間に1つ別の原子が結合しているHとN(例:H-C-N)、3JHHは間に2つ別の原子が結合しているHとH(例:H-C-C-H)を表します。
各タイプごとにデータ数やscの値の分布が異なってくるため、タイプの違いをどのように扱うかもポイントの一つとなっていました。(全てまとめて予測、○HC, ○HN, ○HHでまとめて予測、各タイプ毎に予測、etc...)
またscの値はFermi Contact (fc)、Spin-dipolar (sd)、Paramagnetic spin-orbit (pso)、Diamagnetic spin-orbit (dso)の4つの値の和として表されます。これらの値はscalar_coupling_contributions.csvとして別途与えられていました。これを活用してscそのものではなくfc、sd、pso、dsoの値を個別に予測してから和をとる方法も取られていました。

Additional Dataについて
メインで与えられたfeatureは分子内の各原子の位置情報のみですが、Additional Dataとして双極子モーメント、マリケン電荷、位置エネルギーなどのデータがtrainにのみ与えられていました。これらを利用するためにはAdditional Dataのtestの値を別モデルで予測する必要があります。
評価指標
評価指標はLog of Mean Absolute Errorで以下の式で表されます。
:scのタイプの数
:各タイプのデータ数
scの8つのタイプごとにLog of Absolute Errorを計算し、それらの平均をとります。
Graph Convolutional Networks (GCN)
コンペ序盤はいかに特徴量を作成するかがメインで、GBTやシンプルなNNによる解法が中心でしたが、中盤から終盤にかけてはけろっぴ先生のStarterKitを皮切りにGCNによる解法が注目されるようになりました。
GCNではグラフ構造における畳み込み演算を定義しNNを構成します。分子は原子をノード、結合をエッジとしたグラフ構造としてみなすことができるため、その物性予測等にGCNを用いることができます。記述子をインプットとする従来の機械学習手法では局所構造しか考慮することができないという問題がありました。GCNには注目する原子近傍の情報を畳み込みによってうまく抽出することで、より適切な範囲の結合の情報を考慮できるというメリットがあります。
以下では特にGoogleによる化合物の物性予測論文で提案されたMessage Passing Neural Networks (MPNN)について説明します。
Message Passing Neural Networks (MPNN)

MPNNでは既存のGCN手法を
- Message functions
とVertex update functions
からなるMessage passing phase.
- Readout function
からなるReadout phase.
の2段階の枠組みとして整理しています。
Message passing phaseではまずmessages(近傍の情報)を対象となるノード
とエッジ
によって更新します。
次に各ノードをmessagesに基づいて更新します。

Readout phaseでは更新されたすべてのノードを元にグラフ全体の特徴を抽出します。

論文中ではmessage functionを としています。ここで
はエッジ
を(ノードの次元数×ノードの次元数)の行列に変換するneural networkです。
またupdate functionとしてはGRU、readout functionとしてはset2setが使用されています。
GCNの本コンペへの適用
既存のGCN研究では分子ごとの物性予測が主な対象となっていました。しかしながら今回のコンペの予測対象は分子内の2つの原子の相互作用です。そのため既存のGCNを適用するにあたっては更新された対象となる2つのノード情報を用いる必要があります。(分子全体を考えるReadout phaseは不要となる?)

けろっぴ先生のStarterKitでも説明されています。
その他GCNモデル
MPNN以外にdiscussionやkernelで話題に挙がっていた幾つかのGCNモデルをまとめます。
- WeaveNet: 分子内のbond featureではなく、2つの原子のpair featureを利用するモデル (chainer-chemistryを用いたkernel)
- SchNet: 原子の位置情報を陽に扱うモデル(chainer-chemistryを用いたkernel)
- Path-Augmented Graph Transformer Network: 近傍の情報だけでなく2原子間のpath featureを利用+Transformer機構の利用(githubリポジトリ)
- Augmented-GCN: Attention機構+Gated skip-connectionの利用(githubリポジトリ)
GNNの参考資料
GNNに関して参考となる資料のリンクをまとめます。
- A Comprehensive Survey on Graph Neural Networks: GNNに関する包括的なサーベイ論文
- Must-read papers on GNN: 重要なGNN論文をまとめたリポジトリ1
- Must-read papers and continuous tracking on Graph Neural Network(GNN) progress: 重要なGNN論文をまとめたリポジトリ2
最後に
本記事では分子コンペの振り返りということで、コンペの概要からGCNの適用についてまで簡単にまとめました。上位陣の解法を読む際などにお役立て頂ければと思います。